文本的复杂度度量
如果把文本的理解过程看作一个概念学习的过程,把阅读一篇文本的过程看作文本语境形成的过程,那么我们可以借鉴人类概念学习的复杂度来度量文本的复杂度。从阅读的认知体验看,文本的复杂度直接影响文本的可理解性,它是文本度量的一个重要的指标。
本章讲解一种基于人类概念学习的布尔表达式复杂度的文本复杂度度量方法。通过定义文本语境的复杂度和文本理解的难度来模拟人的阅读体验,度量文本语境在认知过程中的作用;此度量方法的正确性可通过定量分析的方法从语言学和认知科学两个方面得到了验证。基于文本语境复杂度的度量方法可以为评估广告推送质量、网络问答系统的构建、电子商务中的商品推荐等。
人类概念学习的复杂度度量方法
2000 年 Nature 杂志上发表了一篇认知科学方面的论文,题为“人类概念学习的布尔表达式复杂度的最小化”。它首次通过化简布尔表达式来度量人类概念学习的复杂度。根据认知科学中对人类概念学习的研究,有一个简单而符合经验的规律:一个概念的主观难度正比于它的布尔表达式的复杂度。一个概念的布尔表达式的复杂度就是与这个概念等价的最短布尔表达式的长度,通常长度就是变量的总个数(包含正反变量)。为了方便书写我们用 ab 代替a∧b(且),a+b代替a∨b(或),a'代替┐a(非)。
例如,概念ab+ab'等于a(b+b'),这样就等于a,所以有概念复杂度1;由于ab+a'b'没有更短的表达式,所以概念复杂度是4;布尔表达式的复杂度实际上是一种内在数学复杂度的常用度量方法,也是概念的不可压缩性的体现。发现特定表达式的最短等价表达式是一个 NP 难的问题。实际中通过一些近似的计算技术(如因数分解)化简表达式。
假设有一个概念包括n个特征和m个对象,这样一个概念可以表达为m个分离的n个特征联合的累加和,通常表示成一个分离的常规表达式(disjunctivenormal formula,DNF)。因此,这样一个概念可以表达为一个包含m×n个变量的DNF。DNF 是一个完全没有压缩的形式;它逐个描述了符合概念的所有对象。当用启发式的方法对 DNF 化简时,它的长度越来越短。这些布尔表达式的复杂度的值可以准确地预测主观的困难程度。
文本的复杂度相关定义
文本语境的复杂度
假设一篇文本包含m个句子和n个关键词,根据基于关键词在句子上分布的文本语境的表示方法,一个包含m×n个变量的 DNF 可以用来描述文本,DNF 的布尔表达式的复杂度(即 DNF 的最短长度,你可以使用现有的matlab代码化简布尔表达式)被定义成文本语境的复杂度,没有化简的 DNF 长度m × n被定义为文本语境的最大复杂度。
文本理解的难度
根据文本语境的复杂度的定义,文本理解的难度被定义为文本语境的复杂度与文本语境的最大复杂度的比率。文本理解的难度反映了文本语境的复杂度的可压缩性,它可以被用来模拟人的阅读体验,度量文本被读者理解的程度。
文本语境的复杂度之和
假设文本含有m个句子,文本语境的复杂度之和被定义为基于顺序的一个接一个句子的累加而得到的m个不同句子数目的文本语境的复杂度之和。此求和过程可以被用来模拟人的阅读过程,近似度量人在阅读文本时能量的消耗。
基于关键词在句子上分布的文本表示
文本语境d可以表示为:
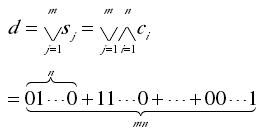
上式中s_j表示第j个句子;c_i表示第i个关键词;符号∧表示一个句子中的关键词之间的组合关系;符号∨表示文本中的句子之间的连接关系。在一个句子中,每个关键词有两个状态,“出现”和“不出现”,记为“1”和“0”。所以文本语境最后可以转换成01的形式。
实例
简单实例
假设有一段对话在两个人之间,记为 A 和 B。
A: Can you tell me the **time**?
B: The **milkman** has just left.
从对话中抽取两个关键词(对话中被加粗表示),即 time(用符号a表示)和milkman(用符号b表示)。根据上面的认知科学的背景知识以及单篇文本的形式化方法,这个对话可以用一个多项式表示ab'+a'b。因为这个多项式无法化简,所以它的文本语境的复杂度是4。这样它的文本理解的难度是1。如果没有任何语境(背景知识),我们很难理解这段对话,现在我们加入一个语境如下:
The **time** is 6 am of the **milkman** leaving.
那么上面的对话可以用一个多项式ab'+a'b+ab表示,则它的文本语境的最大复杂度是6;通过启发式方法可以化简为多项式a+b,则它的文本语境的复杂度是2。因此,这段对话的文本理解的难度是0.333。
三个关键词和四句话的实例
假设有一段对话在两个人之间,记为 A 和 B。
A: How much **power** do you have?
B: I have read a lot of **books**.
抽取两个关键词(对话中被粗体表示),即 power (a)和 book (b),那么这段对话可以被一个多项式表示 ab'+a'b。由于该多项式无法化简,所以它的文本语境的复杂度是4。这样文本理解的难度是1。如果没有语境,我们可能无法理解这段对话。现在加入一些常识和背景知识如下:
There is a lot of **knowledge** in **books**.
Bacon said “**knowledge** is **power**.”
我们可以抽取三个关键词(对话中被粗体表示),即 power (a),book (b),knowledge (c)。那么上面的对话可以由一个多项式表示ab'c'+a'bc'+a'bc+ab'c,它的文本语境的最大复杂度是 12。通过启发式方法,它的最短布尔表达式为ab'+a'b,则它的文本语境的复杂度是4。因此,文本理解的难度是0.333。
应用
论文摘要阅读
从国际会议WWW2005中,我们选出一篇论文,它的题目为“Duplicate Detection in Click Streams”。它的摘要包含 5个句子,记为。从论文的题目中我们提取4个关键词(摘要中被粗体表示),即 duplicate (a) , detection (b) , click (c) , 和 stream (d)来描述文本理解的难度。这里我们把标题看作一个概念的简单描述,摘要作为这个概念的详细描述。由于布尔表达式的复杂度化简是一个 NP 难的问题,实际运用中变量个数不能太多,所以从标题中提取关键词近似地代替从正文中提取关键词。然后,我们基于一个接一个句子的顺序累加来模拟阅读过程,通过上面的方法计算不同句子数目下的文本理解的难度,就可以得出一些关于本文的阅读结论,如在文本阅读过程中当一个主题意群被阐述完之后,文本理解的难度会明显的下降。在文本阅读过程中当一个主题刚刚被阐述且没有完成时,文本的理解难度会有轻微的上升。由于上面的结论符合人的阅读体验,所以,文本语境复杂度的度量方法可以一定程度的反映人的阅读体验。